
[알고리즘] 정렬
정렬
- 주어진 데이터를 값의 크기 순서에 따라 재배치하는 것
내부정렬 vs 외부정렬
- 정렬 수행 시점에 데이터가 어디에 저장되어 있는가?
- 내부정렬
- 전체 데이터를 주기억장치에 저장한 후 정렬을 수행하는 방식
1) 비교 기반 알고리즘
- 알고리즘의 성능 = 비교횟수
- 선택정렬, 버블정렬, 삽입정렬, 셸정렬 (O(n^2^))
- 퀵정렬, 합병정렬, 힙정렬 (O(nlogn))2) 데이터 분포 기반 알고리즘
- 알고리즘의 성능 = 데이터의 이동 횟수 (O(n))
- 계수정렬, 기수정렬, 버킷정렬
- 사전에 데이터 정보를 알아야 하기에 일반적으로는 비교기반을 사용 - 전체 데이터를 주기억장치에 저장한 후 정렬을 수행하는 방식
- 외부정렬
- 모든 데이터를 주기억장치에 저장할 수 없는 경우, 보조기억장치에 저장해 두고 일부 데이터만을 반복적으로 주기억장치에 옮겨와 정렬을 수행
- 모든 데이터를 주기억장치에 저장할 수 없는 경우, 보조기억장치에 저장해 두고 일부 데이터만을 반복적으로 주기억장치에 옮겨와 정렬을 수행
기본 개념
- 안정적 정렬
- 동일한 값을 갖는 데이터가 여러 개 있을 때 정렬 전의 위치가 정렬 후에도 유지가 되는 정렬
- 제자리 정렬
- 동일한 값을 갖는 데이터가 여러 개 있을 때 정렬 전의 위치가 정렬 후에도 유지가 되는 정렬
- 제자리 정렬
- 입력 배열 이외에 별도로 필요한 저장 공간이 상수 개를 넘지 않는 정렬
- 입력 크기 n이 증가함에도 불구하고 추가적인 저장 공간은 증가하지 않음
- 입력 배열 이외에 별도로 필요한 저장 공간이 상수 개를 넘지 않는 정렬
- 기본 가정
- 기본 가정
- 입력 데이터의 크기는 양의 정수이며, A[0~n-1]로 구성
- 입력 크기는 n
- 기본적인 정렬 방식은 오름차순
선택 정렬
- 입력 데이터의 크기는 양의 정수이며, A[0~n-1]로 구성
- 입력 배열에서 가장 작은 값부터 순서대로 ‘선택’해서 나열하는 방식
- 입력 배열에서 가장 작은 값부터 순서대로 ‘선택’해서 나열하는 방식
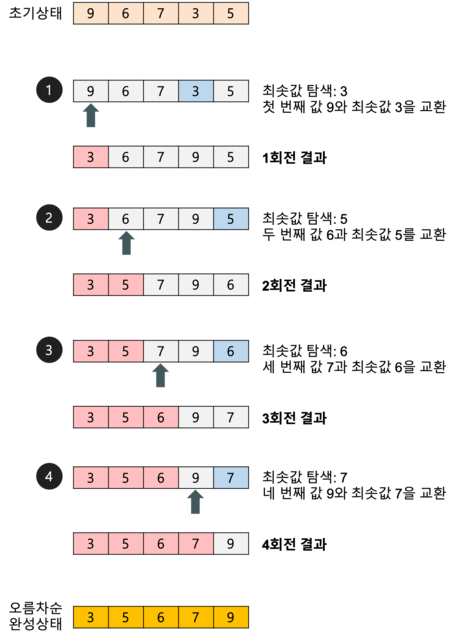
for(i=0; i<n-1; i++){ //(n-1)번 반복
min = i;
for(j=i+1; j<n; j++){ //A[i...ㅜ-1]에서 최솟값 찾기
if(A[min]>A[j]) min = j;
}
A[i]와 A[min]의 자리 바꿈 로직; // 최소값과 A[i]의 위치 교환
}
- 특징
- 입력 데이터의 순서에 민감하지 않음. 미정렬 분에 대해 항상 (n-1)-i번의 비교가 필요
- 입력 데이터의 상태와 상관 없이 항상 동일한 성능 O(n^2^)을 가짐
- 제자리 정렬 알고리즘임. 입력배열 A[n]외에 i, j, min, tmp 4개의 저장 공간만 필요
- 안정적이지 않은 정렬 알고리즘임. 정렬 과정에 순서가 바뀔 수 있음
- 입력 데이터의 순서에 민감하지 않음. 미정렬 분에 대해 항상 (n-1)-i번의 비교가 필요
| 성능 | 제자리 정렬 | 안정적 정렬 |
| O(^2^) | O | X |
버블 정렬
- 모든 인접한 두 데이터를 차례대로 비교해서 왼쪽 데이터가 더 큰 경우에는 오른쪽 데이터와 자리를 바꾸는 과정을 반복해서 정렬을 수행하는 방식
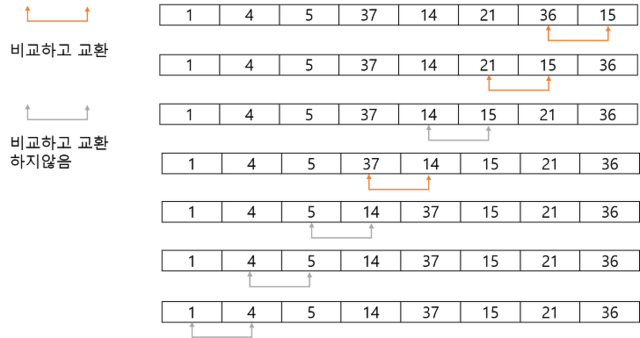
for(i=0; i<n-1; i++){ //(n-1)번 반복
for(j=0; j<n-1; j++){
if(A[j]>)A[j+1]) A[j]와 A[j+1] 자리 바꿈 로직;
}
}
- 특징
- 안정적인 알고리즘임. 인접한 두 데이터가 같은 경우 위치 교환이 발생하지 않음
- 제자리 정렬 알고리즘임. 입력배열 A[n]외에 i, j, tmp 3개의 저장 공간만 필요
- 선택 정렬에 비해 데이터 교환이 많이 발생. 선택 정렬보다 비효율적
- 선택 정렬에 비해 데이터 교환이 많이 발생. 선택 정렬보다 비효율적
| 성능 | 제자리 정렬 | 안정적 정렬 |
| O(^2^) | O | O |
개선된 버블 정렬 알고리즘
- 각 루프의 반복 횟수를 줄여서 개선 가능
- 자리 바꿈이 발생하지 않으면 이미 정렬된 상태이므로 처리단계를 수행하지 않고 종료
- 자리 바꿈이 발생하지 않으면 이미 정렬된 상태이므로 처리단계를 수행하지 않고 종료
- 인접한 두 데이터의 비교 횟수
- 각 단계에서 두 데이터를 무조건 오른쪽/왼쪽 끝까지 이동하면서 인접한 두 데이터의 비교가 불필요
- 이미 제자리를 잡은 데이터에 대해서는 비교를 수행하지 않도록 함
- 각 단계에서 두 데이터를 무조건 오른쪽/왼쪽 끝까지 이동하면서 인접한 두 데이터의 비교가 불필요
for(i=0; i<n-1; i++){
sorted = true; //이미 정렬된 상태라고 가정
for(j=0; j<n-i-1; j++){ //이미 자리 잡은 범위는 배제
if(A[j]>A[j+1]) {
A[j]와 A[j+1] 자리 바꿈 로직;
sorted = false; // 자리 바뀌면 미정렬 상태로 변경
}
}
if(sorted == true) break; // 이미 정렬된 상태면 종료
}
- 정리
- 시간 복잡도는 동일하게 O(n^2^)
- 입력 데이터의 상태에 따라 성능이 달라짐. 이미 원하는 순서로 정렬된 경우 비교 횟수가 줄어듬
- 최선의 경우 : O(n)
- 시간 복잡도는 동일하게 O(n^2^)
삽입 정렬
- 주어진 데이터를 하나씩 뽑은 후 이미 나열된 데이터가 항상 정렬된 상태를 유지하도록 뽑은 데이터를 바른 위치에 삽입해서 나열하는 방식
- 입력 배열을 정렬 부분과 미정렬 부분으로 구분해서 처리
- A[0]를 정렬부분, A[1…n-1]은 미정렬 부분으로 취급해서 시작
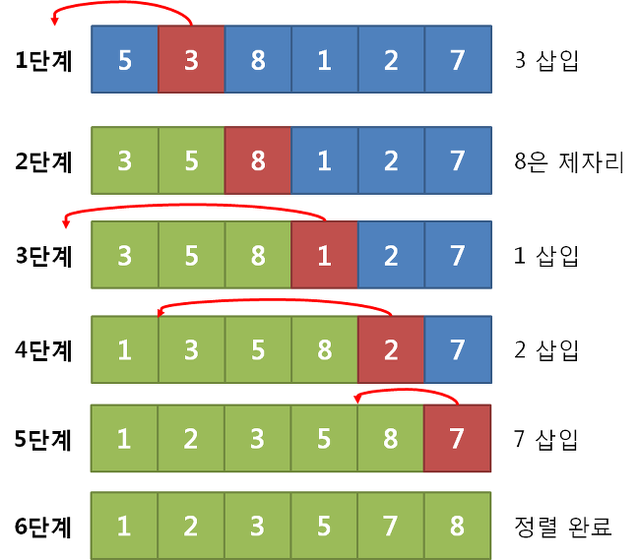
for(i=1; i<n; i++){ //A[0]은 정렬부분, 1~n-1까지 반복
val = A[i]; //미정렬 부분 A[i..n-1]의 첫 번째 데이터 선택
for(j=i; j>0&&A[j-1]>val; j--){ //삽입할 위치 찾기
A[j] = A[j-1]; //데이터 변경
}
A[j] = val;
}
- 특징
- 인접한 두 데이터가 정렬되지 않았을 때만 정렬되기에 안정적인 정렬 알고리즘임
- 입력배열 A[n]외에 i, j, val 3개의 저장 공간만 필요하기에 제자리 정렬 알고리즘임
- 입력 데이터의 원래 순서에 민감함. 이미 원하는 순서로 정렬된 경우 비교 횟수가 줄어듬
- 최선의 경우 : O(n)
- 인접한 두 데이터가 정렬되지 않았을 때만 정렬되기에 안정적인 정렬 알고리즘임
| 성능 | 제자리 정렬 | 안정적 정렬 |
| O(^2^) | O | O |
쉘 정렬
- 삽입 정렬의 단점을 보완
삽입정렬은 현재 삽입하고자 하는 데이터가 삽입될 제 위치에서 많이 벗어나 있어도 한 번에 한 자리씩만 이동해서 찾아가야 함 - 멀리 떨어진 데이터와의 비교, 교환으로 한번에 이동할 수 있는 거리를 늘려서 처리 속도 향상
- 처음에는 멀리 떨어진 두 데이터를 비교해서 필요시 교환하고, 점차 가까운 위치로 비교하며 맨 마지막에 인접한 데이터와 비교,교환
- 입력 배열을 부분 배열로 나누어 삽입 정렬을 수행하는 과정을 부분배열의 크기와 개수를 변화시켜가며 반복
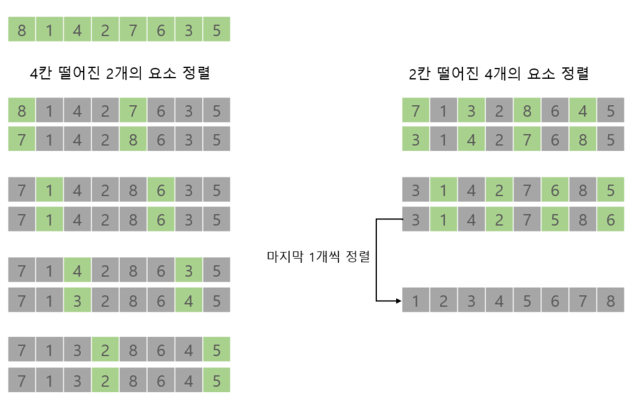
for(int gap=n/2; gap>0; gap/=2){ //gap=부분배열의 개수&간격의 크기
for(i=gap; i<n; i++){ //gap개의 부분배열에 대한 삽입과정
val = A[i];
for(j=i; j>=gap&&A[j-gap]>val; j=j-gap){
A[j] = A[j-gap];
}
A[j] = val;
}
}
- 특징
- 사용하는 순열에 따라 성능이 달라짐. 가장 좋은 간격을 찾는 것은 아직 미해결 과제
- 최선의 경우 : O(nlogn)
- 최악의 경우 : O(n^2^)
- 배열에 따라 순서가 바뀌기에 안정적이지 않은 정렬 알고리즘임
- 입력배열 A[n]외에 gap,i, j, val 4개의 저장 공간만 필요하기에 제자리 정렬 알고리즘임
- 사용하는 순열에 따라 성능이 달라짐. 가장 좋은 간격을 찾는 것은 아직 미해결 과제
| 성능 | 제자리 정렬 | 안정적 정렬 |
| O(^2^) | O | X |